头节点高可用
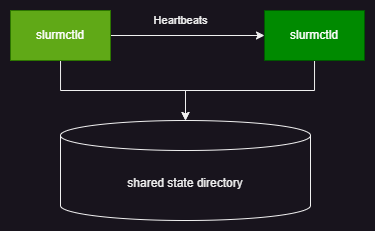
fsched支持头节点主备方式的高可用. 通过配置fsched的头节点高可用, 可以实现头节点的高可用性. 当头节点发生故障时, fsched会自动切换到备用头节点, 保证服务的连续性. 多个头节点之间通过共享文件系统来传递状态信�息, 以保证状态的一致性.
术语
头节点: 负责承载fsched控制器的节点 主节点: 头节点中, 在正常情况下负责处理任务的头节点. 从节点: 头节点中, 负责热备的节点.
前置条件
头节点HA通过一个文件系统来传递状态信息, 所以需要一个共享的文件系统. 一般由一个可靠的NFS系统提供. 为了保证HA的可靠性, 需要确保NFS系统的可靠性, 并且该NFS至少需要提供以下性能 (因为这个共享存储为所有集群共享, 以下为每个承载集群需求):
- 读性能: > 10 reads/s 和 300 KB/s
- 写性能: > 100 writes/s 和 10000 KB/s
- 容量: > 10GB
这个共享文件系统需要在平台配置中通过以下配置项指定:
配置头节点HA
在配置了共享状态目录以后, 当集群头节点数量大于1时, 头节点高可用自动开启.
头节点HA工作原理
- fsched按照头节点主机名排序, 第一个为主节点. 其他为备用节点.
- 主节点通过定期(~15s)向备用节点发送heartbeat信号, 以及共享目录来通知备用节点头节点的状态.
- 当主节点发生故障时, 该heartbeat会超过配置的时间 (~30s). 备用节点会开始替代主节点的工作.
- fsched中其他客户端组件, 会根据配置, 通过轮训的方式来检查头节点的状态, 以及切换到备用节点.
头节点HA异常后的处理
头节点异常后的集群状态
因为头节点的特殊性, 平台不会对头节点做假设. 特别是本地系统中, 因为无法确切知道节点的运行状态. 平台不会自动剔除头节点. 所以当任何一个头节点发生异常以后, 平台无法正常下发配置到集群.
头节点恢复
当头节点异常后, 备用节点会接管头节点的工作. 如果头节点的异常已经解决, 需要恢复头节点, 按照以下步骤区分处理.
节点恢复
当头节点异常解决以后, 通过界面点击"重新配置"来下发和恢复集群.
头节点替换
当头节点异常无法解决, 需要替换头节点. 需要按照以下步骤来处理:
- 从界面中删除异常的头节点
- 重新添加新的头节点
头节点异常时临时处理
因为主节点异常时, 所有的集群命令和集群节点都会按照配置顺序尝试各个控制节点, 每个节点有一定的超时时间. 所以当明确主节点需要一定时间恢复, 并且业务延迟需要优化的情况下. 可以考虑临时先移除故障节点. 这时候平台会重新配置集群, 选择新的一个节点为主节点.
如果这时需要有集群变更时, 需要先设法恢复头节点.
头节点主从关系
所有slurm组件按照配置顺序尝试各个头节点. 任意时刻只有一个头节点为主节点, 其他头节点为从节点. 主从关系按照以下规则分配:
- 头节点按照主机名顺序分配, 第一个头节点为主节点, 其他头节点为从节点. 例如:
head-1为主节点,head-2为从节点, 以此类推.
常见问题
-
任务在提交过程中, 提示"Job jobid is missing from controller", 并且提交失败.
为了保证控制器的响应速度, 调度性能, 所有任务状态信息是通过异步IO的方式存储在共享磁盘上. 我们尽量保证用户提交后, 立刻开始调度写入任务. 但是任然会因为缓存等各种原因写入不完全. 如果控制器在写入任务状态之前失效, 备份控制器会失去该提交任务的信息, 从而回报任务状态不存在. 用户需要重新提交该任务.
-
主节点失效后,
scontrol ping中看到头节点未切换fsched的主备标识不会随主备切换而改变, 当主节点失效后. "主"和"备"角色不会发生变化, 当备节点接管集群操作后, 备节点变成全功能控制器. 但是其角色在集群中依然是"备"节点. 如果希望重新分配主从关系. 参照头节点异常时临时处理, 重新调整.
-
在节点有异常的情况下, 任务运行时间比预期长
因为fsched记录任务运行时间是通过头节点进行, 如果头节点异常. 在切换期间无法识别和记录任务的结束. 这会导致任务的结束时间比预期长.
-
当头节点异常时, 平台重配置不会完成, 会一直显示配置中.
因为头节点的特殊性, 平台不会自动剔除头节点, 当有任何一个头节点异常时, 为了防止头节点出现配置差异, 平台不会下发配置到集群中. 集群状态会一直显示"配置中". 直到用户手动干预, 去掉异常节点后, 平台重新选择主节点, 下发配置.